この記事とは
- 拡散モデルの初歩的なモチベについてまとめてみた
- 特にScoreとは何か, 拡散モデルではDenoisingをすると言われるが, ScoreとDenoisingはどういう関係性にあるのかに注目して記述した
- この記事の執筆にあたってはこのAyan DasさんのICLR 2024 BlogpostsであるBuilding Diffusion Model’s theory from ground upを多いに参考させて頂きました.
- もし英語が読めるならこちらを読んでください…
“Score"とは?
真の確率分布$p(x)$を考えたとき, そのScore $s(x)$は以下のように, $$\nabla_x \log p(x) := s(x), $$ 真の確率分布の対数を取ったもの(=対数尤度)の勾配として定義される.
これは対数尤度の勾配, つまり対数尤度が増加する方向を指す. つまり言ってしまえば「データ空間上で今の点からどの方向に動けば良いデータが手に入るか」をScoreは教えてくれるのだ.
下記の画像は簡単な二次元正規分布とそのScore(矢印)を可視化したものである.
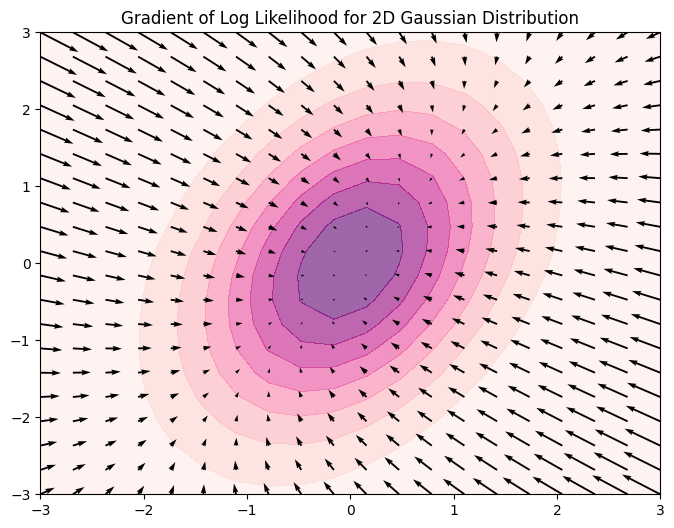
Scoreは便利
確率分布とは簡単に言ってしまえば全空間で積分したら$1$になる非負の関数1である. 空間の部分で積分したらその部分の確率が現れる.
さて突然だがなんかいい感じな確率分布を自作してみよう.
$y=\exp(\tan(\sin(\cos(x))))$みたいにとても複雑な分布を素朴に作って遊んでみよう.
確率分布も関数なので好き勝手に複雑にして良い.
非負はまあ守れるだろう. 積分したら$1$という条件があるが, これも好き勝手に複雑にした後に全体を正規化(=用意した関数を全空間で積分したもので割る)すればどうにでもなる. なので,
$$p_\text{ExtremeComplex}(x)=\frac{\text{NonNegativeExtremeComplexFunction(x)}}{\displaystyle \int_x \text{NonNegativeExtremeComplexFunction(x)} dx}, $$ というノリでいくらでも複雑な分布が用意できるのだ!!!…本当か?
$\displaystyle \int_x \text{NonNegativeExtremeComplexFunction(x)} dx$は本当に計算できるのだろうか.
いやそんなことはないだろう.
積分計算は難しく, 解析解が得られることはほとんどなく, 近似計算も非積分関数が複雑, もしくは積分空間が高次元になれば極めて難しくなる.
そのため適当にデザインした複雑な確率分布では正規化係数(分配関数とも呼ばれる)が計算できず, 結果として各点の確率分布の値が計算できなくなる.
Scoreはこの問題を解決してくれる.
例えば上の$p_\text{ExtremeComplex}(x)$のスコアを求めてみる. $$ \begin{aligned} s_{\text{ExtremeComplex}}(x)&=\nabla_x \log p_\text{ExtremeComplex}(x)\\ &= \nabla_x \text{NonNegativeExtremeComplexFunction(x)} \\ &\quad \quad - \underbrace{\nabla_x \int_x \text{NonNegativeExtremeComplexFunction(x)} dx}_{=0(\text{定数なので})} \\ &= \nabla_x \text{NonNegativeExtremeComplexFunction(x)} \end{aligned}$$ そう, 積分計算は定数なので微分されて消えるのだ.
このように本来は積分が計算できなくて求められない複雑な分布でもScoreは求められる.
これはニューラルネットワークを特徴付けに利用した確率分布といった複雑な分布を使用する場合において強く便利である.
微分された世界と微分される前の世界が持っている情報の差がほとんど無いことを考えると, Scoreは非常に扱いやすい概念だとわかるだろう.
Scoreを使ったサンプリング
Scoreはデータのサンプリングに有用である.
機械学習のモデルの最適化では勾配降下法(もしくは上昇法)2を利用することを考えたら, Scoreを使用して任意の点(=本当に適当なデータ)から良い点(=高い対数尤度を持つ点)にたどり着けるかもしれないと想像できる.
実際Naiveにモデル$f_\theta$に対する最急降下法, $$\theta\leftarrow \theta+\eta \nabla_\theta f_\theta(x), $$ に適用するように, Scoreを使用したサンプリングも $$x \leftarrow x+\delta \nabla_x s(x), $$ というように実装できる.
実際このように実装したサンプリングアルゴリズムはある程度は機能する. 実際ナイーブに実装したものが以下となる.
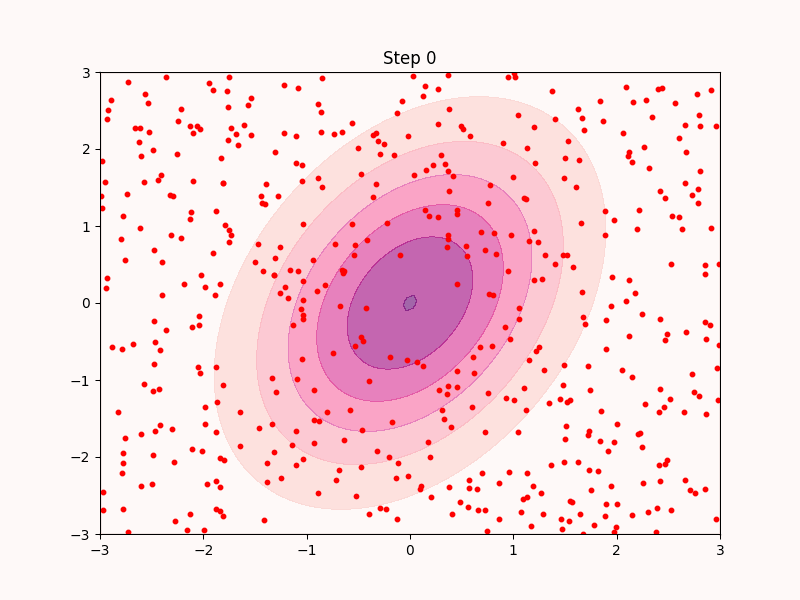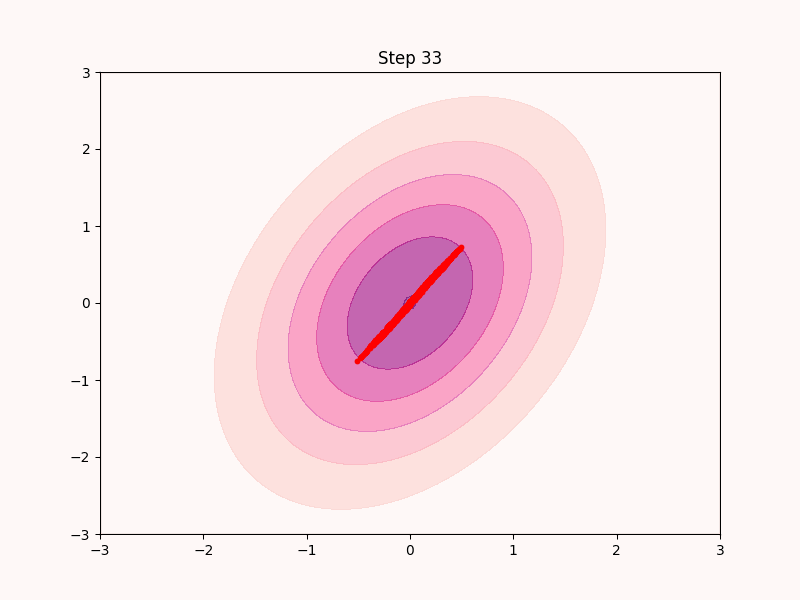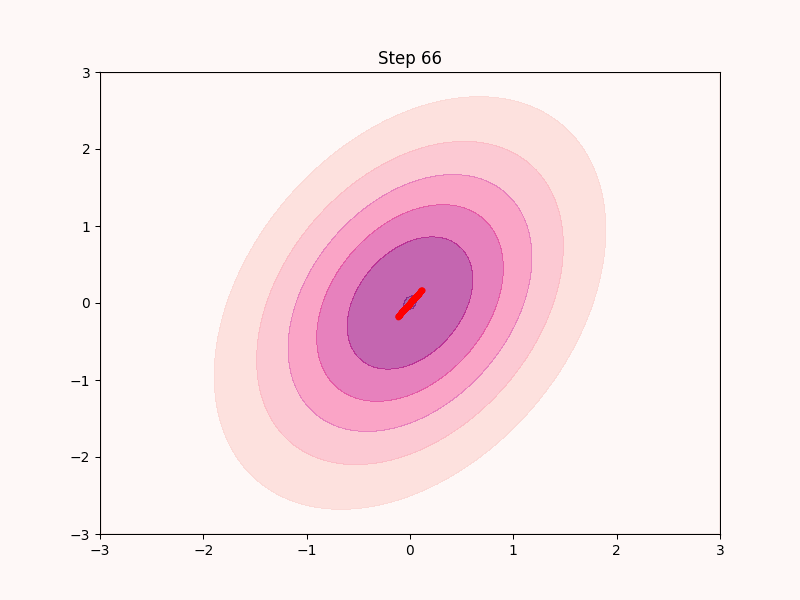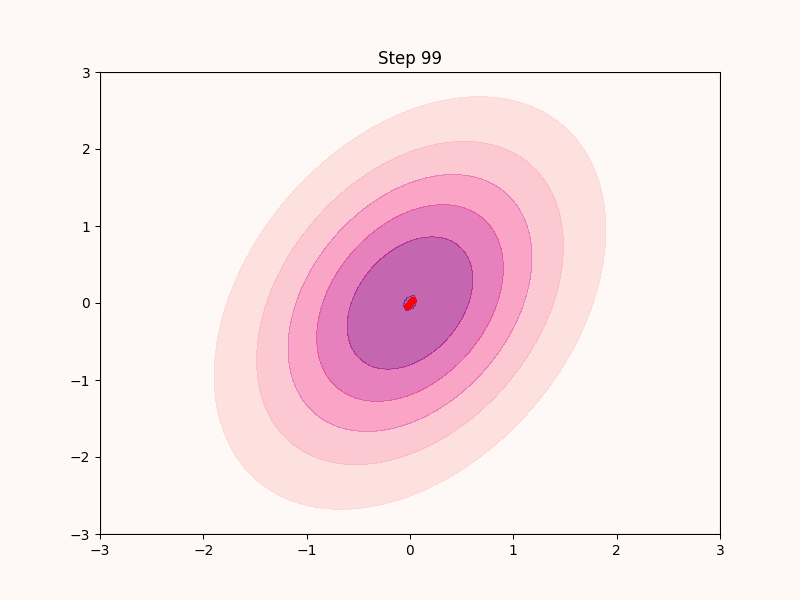
上のgifからも分かる通りこのアルゴリズムは最急上昇法と同じくただ登ることしか考えておらず, すぐに局所解3に収束してしまい, 低密度領域は全くサンプリングできていない.
ではどうすれば良いかというと, 確率的勾配降下法や他のサンプリング手法と同じように乱数を入れることが必要だ.
まずNaiveなサンプリングにおいて $\delta\rightarrow 0$とすると$dx = s(x) dt$となる.
ここで以下のように, $$dx = s(x) dt + \text{RandomNoise}, $$ とやってみればいいのではと想像する. 実際にこれは以下のように機能する.
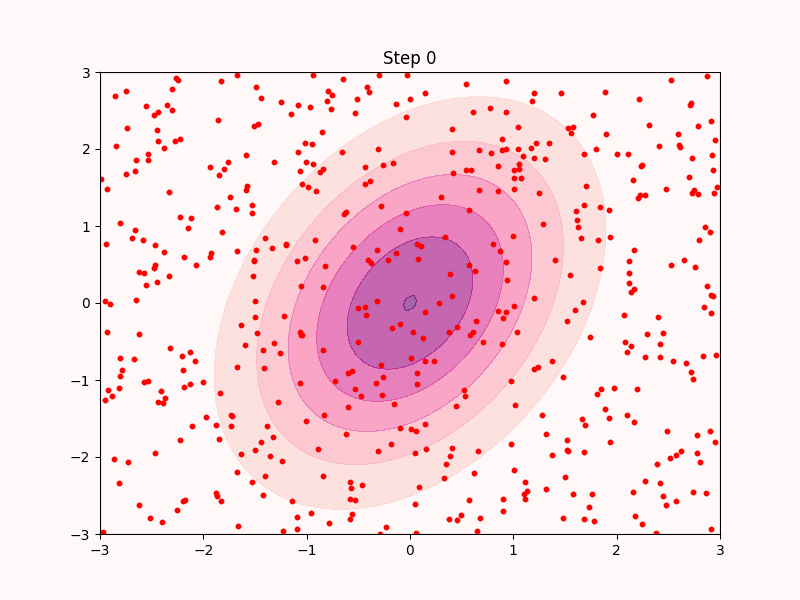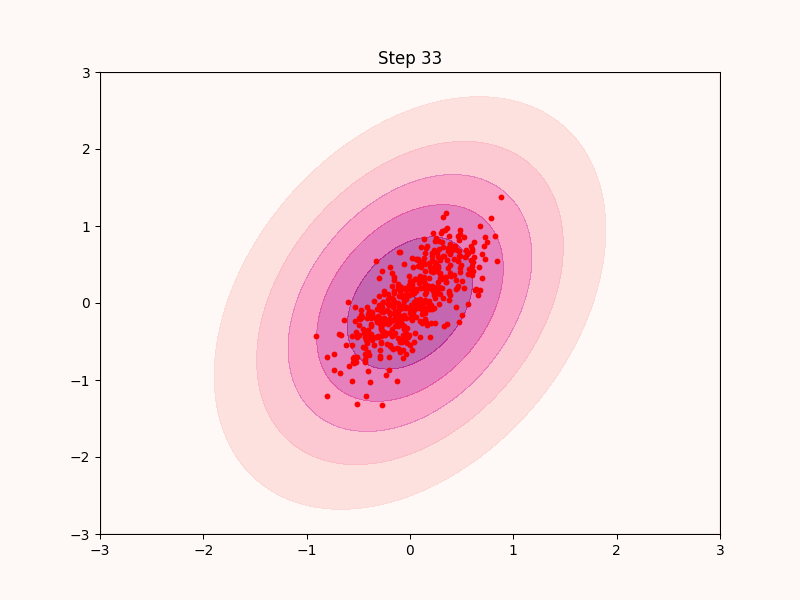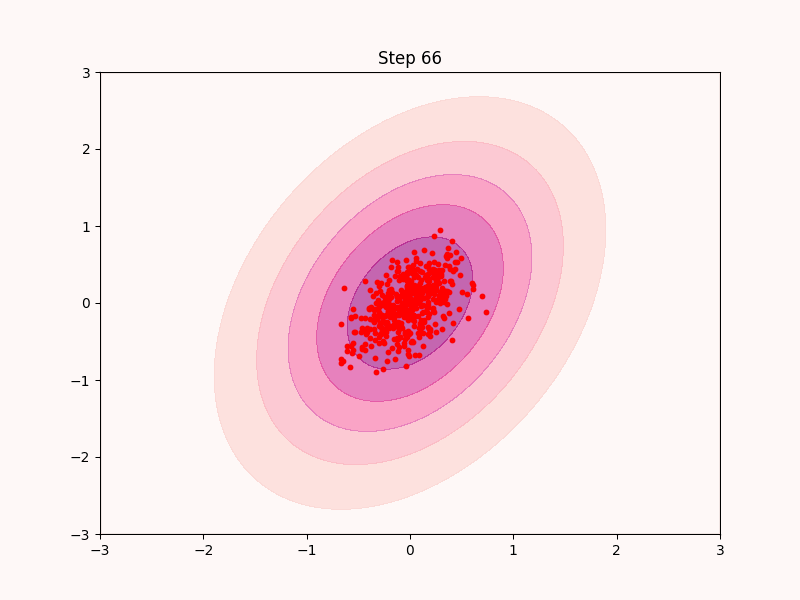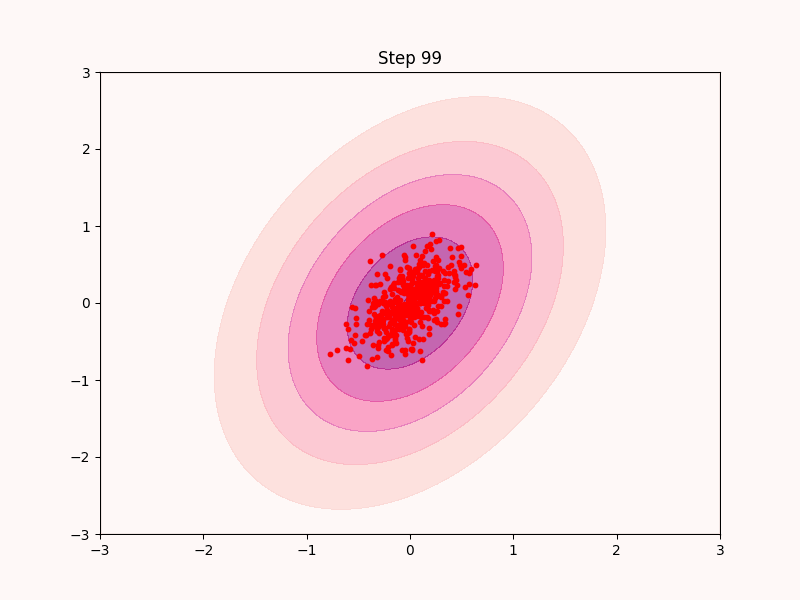
先ほどの最急上昇法と違い, 最頻値以外の部分も高ステップにおいてサンプリングできていることが分かる.
これをちゃんとやっているのがLangevin Dynamicsと呼ばれる古典的で極めて重要なアルゴリズムだ.
Langevin Dynamics
Langevin Dynamicsは以下のような確率微分方程式, $$dx = -\nabla_x U(x) dt + \sqrt{2}dB_t, $$ で定義される.
- $U(x)$はポテンシャルエネルギーである.
- 物理学では物体は高いエネルギーを持つ状態が不安定であり, 自ずと安定状態たる低いエネルギーの状態に向かうとされる.
- これは統計学における(対数)尤度とは逆の概念でありポテンシャルエネルギーは負の対数尤度と概念的に一致すると考えて良い.
- $B_t$はブラウン運動におけるノイズである.
- その本性は無限小時間でのガウシアンノイズ, つまり $$dB_t=N(0,dt) \Rightarrow dB_t=\sqrt{dt}\cdot z,\text{where} z\sim \mathcal{N}(0, I)$$ である
- 機械学習ではポテンシャルエネルギー$U(x)$を負の対数尤度だと解釈して, $$dx = s(x) dt + \sqrt{2}dB_t, $$ という形を使うことが多い. まさにNaiveなアプローチにノイズを加えた形である.
Langevin Dynamicsはマルコフ連鎖モンテカルロ法(MCMC)の一種であり, 分布のScoreがあればその分布からデータをサンプリングする一般的な手法として使われる.
Scoreの推定: Score Matching
今まで述べたことは
- Scoreはデータ空間上での対数尤度の勾配であり, 良いデータを手に入れるにはどの方向に向けば良いかを教えてくれる
- Scoreは確率分布本体より求めやすいことが多い(正規化係数の積分計算を回避)
- Langevin Dynamicsを使えばScoreからデータのサンプリングができる
である.
Score便利そうである, イケイケなのである, データの真の確率分布のScoreがあればサンプリングできるので使いたいのである. 一方でこれらは全てScoreがあるという前提の話だ.
ではScore自体を手に入れるにはどうすればのだろうか.
まず定義に従って$\nabla_x \log p(x) := s(x)$で計算してみようとするが, これはほとんどの場合においては無理だろう. なぜなら真の確率分布はアクセスできない場合がほとんだからだ4.
ではどうすればいいのだろうか. ここからはScoreを求めるためのアルゴリズム, Score Matchingについて簡単にレビューする.
Explicit Score Matching
仮に真の分布のScore$\nabla_x \log q_{\text{data}}(x)$にアクセスできるなら, Scoreを近似するためにparametrizeした関数$s_\theta(x)$を使って,
$$ J_E(\theta)=\frac{1}{2}\mathbb{E}_{x\sim q_{\text{data}}(x) } \displaystyle \Bigg \lbrack\Bigg\lVert s_\theta(x)-\nabla_x \log q_{\text{data}}(x)\Bigg\rVert ^2 \Bigg\rbrack,$$ を目的関数にして学習をすることができるだろう. もちろんこれは無理だが, 最も自明なアプローチなのでExplicit Score Matchingと呼ばれる.
Implicit Score Matching
Aapo Hyvärinenは$2005$年に上のExplicit Score Matchingに変わる目的関数として以下のImplicit Score Matching $J_I(\theta)$を提案した. $$J_I(\theta) = \mathbb{E}_{x\sim q_{\text{data}}(x) } \displaystyle \Bigg \lbrack \text{Tr}\left(s_\theta\left(x\right)\right)+\frac{1}{2}\lVert s_\theta\left(x\right)\rVert ^2 \Bigg\rbrack.$$
Implicit Score MatchingはExplicit Score Matchingと違って, 真のScore$\nabla_x \log q_{\text{data}}(x)$を期待値の中に含んでない. そのため真の確率分布からのサンプリングデータ(=データセット)だけで近似計算できるので使用できる目的関数だ.
今回は証明は省略するが, Explicit Score Matchingとは以下の式のように定数項の違いしかない.
$$J_E(\theta) = J_I(\theta)+C_1. $$
そのため, Implicit Score MatchingとExplicit Score Matchingは最適解が一致する. それにも関わらずImplicit Score Matchingでは計算に真のScoreが出てこない5.
Denoising Score Matching
Implicit Score MatchingはExplicit Score Matchingと違って真のScoreが出てないこないので計算でき、さらに最適解も真のものと一致するという優れものだ.
一方で実は計算コストが高い問題がある. その原因は$J_I$の中にあるトレース項$\text{Tr}\left(s_\theta\left(x\right)\right)$だ.
これはつまりいわゆるScore関数のヘッシアンを計算することに対応するが, 実用上では非常に計算が遅いという問題がある.
この問題を解決するためにVincent Pascalは2011年にDenoising Score Matchingと呼ばれる目的関数を提案する.
これもImplicit Score Matchingと同じくExplicit Score Matchingと同等(定数項分の差があるだけ)であり, またトレース項が出てこない分より高速に計算できるという特徴を持つ.
Denoising Score Matchingは以下のような式で書かれる.
$$J_D(\theta) = \mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2}\Bigg\lVert s_\theta\left(x+\sigma\epsilon\right)-\left(-\frac{\epsilon}{\sigma}\right) \Bigg \rVert ^2 \Bigg\rbrack.$$
同様にDenoising Score Matchingも同じくExplicit Score Matchingと同等である. 証明は同じく省略する. $$J_E(\theta) = J_D(\theta)+C_2. $$
それ以外のScore Matchingとして近年ではImplicit Score Matchingの改良としてSliced Score Matchingと呼ばれる手法があるがここでは紹介を省略する.
何が"Denoising"なのか
Denoising Score Matchの式を詳しく見ていこう. 以下の再掲する. $$J_D(\theta) = \mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2}\Bigg\lVert s_\theta\left(x+\sigma\epsilon\right)-\left(-\frac{\epsilon}{\sigma}\right) \Bigg \rVert ^2 \Bigg\rbrack.$$
Implicit Score Matchingが何が変わっただろうか.
まずトレースを含む項がないことがわかるだろう. これはそれが狙いだから当然ではあるが, 計算上のボトルネックがなくなったので非常に嬉しい.
次に期待値を取っている分布が変わっていることがわかるだろう. もともとは$q_{\text{data}}(x)$だけだったが, そこに$\mathcal{N}(0,I)$が加わっている. これはどういうことだろうか.
さらに期待値を取っている中身も変わっている. Score関数の引数がただの$x$ではなく$x+\sigma\epsilon$になっているし, 予測Scoreが$\left(-\frac{\epsilon}{\sigma}\right)$に一致ことを目的関数が要求している. これはなんだろうか.
ここからはDenoising Score Matchingのイメージについて解説する.
Denoising Score Matchingは一言で言えば分布をノイズで摂動させ, 摂動させる前への戻し方を学習することに対応する.
このことを良く見るために式をいじってみる.
$$ \begin{aligned} J_D(\theta) &= \mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2}\Bigg\lVert s_\theta\left(\underbrace{x+\sigma\epsilon}_{:=\tilde{x}}\right)-\left(-\frac{\epsilon}{\sigma}\right) \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2}\Bigg\lVert s_\theta\left(\tilde{x}\right)-\left(-\frac{\epsilon}{\sigma}\right) \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2\sigma^2}\Bigg\lVert \underbrace{-\sigma s_\theta\left(\tilde{x}\right)}_{:=\tilde{\epsilon}_\theta(x)}-\epsilon \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2\sigma^2}\Bigg\lVert \tilde{\epsilon}_\theta(x) -\epsilon \Bigg \rVert ^2 \Bigg\rbrack \\ \end{aligned}$$
式の途中で定義した関数$\tilde{\epsilon}_\theta(x)$を使って, そのデータに乗ったノイズ$\epsilon$を予測する目的関数となった.
もう少しいじってみよう.
$$ \begin{aligned} J_D(\theta) &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2}\Bigg\lVert s_\theta\left(\tilde{x}\right)-\left(-\frac{\epsilon}{\sigma}\right) \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2\sigma^4}\Bigg\lVert \sigma^2 s_\theta\left(\tilde{x}\right)-\left(-\sigma\epsilon\right) \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2\sigma^4}\Bigg\lVert \underbrace{\tilde{x} - \tilde{x}}_{=0}+\sigma^2 s_\theta\left(\tilde{x}\right)-\left(-\sigma\epsilon\right) \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2\sigma^4}\Bigg\lVert \underbrace{\tilde{x} +\sigma^2 s_\theta\left(\tilde{x}\right)}_{:=x_\theta(\tilde{x})}-\underbrace{\left(\tilde{x}-\sigma\epsilon\right)}_{=x} \Bigg \rVert ^2 \Bigg\rbrack \\ &=\mathbb{E}_{x\sim q_{\text{data}}(x), \epsilon\sim \mathcal{N}(0,I) } \displaystyle \Bigg \lbrack \frac{1}{2\sigma^4}\Bigg\lVert x_\theta(\tilde{x})-x \Bigg \rVert ^2 \Bigg\rbrack \end{aligned}$$
今度は式の途中で定義した関数$x_\theta(\tilde{x})$を使って, そのノイズで摂動していない綺麗なデータ$x$を予測する目的関数となった.
このようにDenoising Score Matchingは分布をノイズで摂動させ, 摂動させる前への戻し方を学習しており, 結果としてScoreを学習ことに対応する.
ただ上記の式変形でわかる通り, 変形された式ではもはやScore関数は出てこず, それぞれノイズを予測役割をもったノイズ予測関数$\tilde{\epsilon}_\theta(x)$と綺麗なデータを予測するDenoisingの役割を持ったDenoising関数$x_\theta(\tilde{x})$が出てきている.
実装上でもこれで置かれる場合が多い, つまりScore関数を直接登場させるのではなくニューラルネットワークを使ってDenoising関数などを直接表現することが良く行われる.
重要なので繰り返すが, たとえ最初からノイズ予測関数やDenoising関数を使って目的関数を使っても結果としてScoreは学習される.
ノイズ予測関数やDenoising関数からスコアに変換することも簡単である.
なぜなら上の式から分かる通り, Denoising関数とNoise予測関数とScore関数はそれぞれスケーリングと一次変換分の違いしかなく, それらの変換は容易にできるからだ.
DenoisingとScore:まとめ
現在までの状況を整理しよう.
まず, Scoreが欲しかった.
なぜならばScoreは正規化係数が計算できないという問題を回避し, かつScoreがあればLangevin Dynamicsを使ってデータをサンプリングできるからだ.
そしてScoreを求めるための方法としてScore Matchingと呼ばれる3つの目的関数を紹介した. Explicit Score Matching, Implicit Score Matching, そしてDenoising Score Matchingだ.
繰り返すがどれもScoreを求めるための手法だ.
ただしDenosing Score Matchingではもはや実装上ではScoreを元にする必要がなく, データにかかっているノイズ, もしくはDenoisingされた綺麗なデータを予測することで良い.
そしてDenoising関数とNoise予測関数とScore関数はそれぞれスケーリングと一次変換分の違いしかなく, それらの変換は容易にできる.
Scoreの推定は難しい
今まではScore Matching, つまりScoreを学習する方法を紹介してきた. Scoreが学習できればあとはLangevin Dynamicsでデータをサンプリングできるからだ.
今までの話を統合すればDenoising Score MatchingでScoreを学習して, Langevin Dynamicsを回すのがNaiveだがそれで良いという話になる.
一方で実は現実世界のデータでは往々にしてこの手法じゃうまくいかない. ここではこのNaiveな方法だとなぜうまくいかないのかを解説する.
大きく言って現実世界のデータが持つ二つの性質が原因だとされる. 多様体仮説と多峰性による低密度領域だ.
多様体仮説
多様体仮説とは, 我々が扱う現実世界のデータは高次元だが, それらのデータは高次元空間の中の低次元多様体に埋め込まれている傾向がある, という仮説である.
データにはそれぞれの形式に合った表現方法があると考えるとわかりやすい.
例えば球面は2次元の多様体だが, 3次元以上のユークリッド空間に埋め込むことができるが,高次元になればなるほどデータ本来が持っていた意味が見えなくなる. 現実世界で扱うデータは共通空間のために高次元扱っているが, それぞれのデータは実はさらに低次元で見た方が本質が見えるといった具合である.
この仮説は様々な機械学習・統計学の論文で仮説を裏付けるような結果が示唆されており, 現実世界のデータが持つ一般的性質の一つだとされている.
この仮説が成立するならばScore Matchingは現実世界のデータではうまくいかなくなる.
なぜならばScore Matchingで求めているのは$\nabla_x \log q_\text{data}(x)$の近似解であり, これは多様体仮説で言う高次元空間での勾配である. そのためデータが埋め込まれている低次元空間のことは全く考えていなく, そして当然そこでのScoreも学習していないからだ.
またデータの大部分が局所的に集まっているならばそれもScoreの学習に強い悪影響を及ぼす.
低密度領域は大変
現実世界において真の分布は常に極めて複雑だろう.
その分布は単独の正規分布のようなものでは決してなく, 小さい峰と大きな峰が入り交じる多峰になっているはずだ. そして峰と峰との間には意味がないとして密度低い領域がある, そういった確率分布になっていると想像できる.
この低密度領域はScore MatchingとLangevin Dynamicsの両方に対して悪影響を与える.
まずScore Matchingについてだ.
真の分布で低密度領域ということは, その分だけ手元にあるその領域に対応するデータが少ないということになる. 高次元空間では極めて巨大な空間を考えることを思い出すと低密度領域ではほとんどデータがない場所が多いということもイメージができるだろう. そのためその領域では当然Score Matchingはうまくいかなくなり, 結果として一部の高密度領域を除いてほとんど正しくScoreが推定されないという問題が起きる.
またLangevin Dynamicsにも問題が起きる.
Langevin Dynamicsは多峰性に弱いという問題がある. 例えば簡単な混合ガウス分布を考えて, そこからLangevin Dynamicsでサンプリングしようとしてみる. Langevin Dynamicsは高密度領域を再現するのは早い, ただ一方で峰間の比率を再現するには時間がかかる.
このように低密度領域では学習もサンプリングもいろいろ大変なのだ.
拡散モデルについて
拡散モデルと呼ばれる生成モデルは以上の述べたNaiveなScore MatchingとLangevin Dynamicsを乗り越えるために生まれた.
これは予測問題としてはScoreの予測, もしくはDenoisingの問題を解いていて6, さらにスケーラビリティやサンプリング加速など様々な思慮が入っている.
拡散モデルの詳しいことは次の記事で述べることにする.
結論
このブログでは拡散モデルの基礎的なモチベを理解するために, Scoreを中心に以下のようなことをいろいろ述べた.
- Scoreとは分布の対数尤度の勾配である.
- ScoreがあればLangevin Dynamicsを使ってサンプリングできる.
- Scoreを推定するためのアルゴリズムの種類としてScore Matchingが知られていて, 中でもDenoising Score Matchingが主流的な立場にある.
- Denoising Score Matchingでは実装上ではもはやScoreが出てこずDenoising関数やノイズ予測関数のみの場合があるが, これらはScoreとはスケーリング程度の差しかない.
- 一方で(Denoising)Score Matchingで推定したScoreを使ってNaiveにLangevin Dynamicsを行っても, 多様体仮説や低密度領域などが原因でうまくいかないことが知られている.
- 拡散モデルはこれらの問題を乗り越えるために生まれた機械学習の生成モデルである.
拡散モデルの詳しい話やカバーしていない確率微分方程式については次回以降に述べていくことにする.
参考文献
- Das, “Building Diffusion Model’s theory from ground up”, ICLR Blogposts, 2024.
- Song, “Generative Modeling by Estimating Gradients of the Data Distribution”, 2021
- 岡野原, “拡散モデル データ生成技術の数理”, 岩波書店, 2023.
- Hyvärinen, “Estimation of Non-Normalized Statistical Models by Score Matching”, Journal of Machine Learning Research. 2005.
- Vincent, “A connection between score matching and denoising autoencoders”, Neural computation. MIT Press. 2011.
- Song, “Generative Modeling by Estimating Gradients of the Data Distribution”, In the 33rd Conference on Neural Information Processing Systems, 2019.